

In today's data-oriented landscape, many organizations have invested heavily in pipelines for their analytical and automated processes, and AI implementations are benefiting from this investment as well. Unfortunately, although significant advancements have been made in tools and cloud-based architectures, enterprise organizations still struggle to derive consistent outcomes and gain valid insights into information from modern cloud data platform solutions.
As we have already indicated, a number of the problems that enterprises experience when attempting to utilize their data, or provide analytical capabilities, may not necessarily result from insufficient data or inaccurate dashboards but stem from an overall lack of a fundamental component that is rarely discussed: the need for systematic testing of data integrity.
✨ Key Insights from This Article:
🧱 Why data integrity is the missing foundation of modern data engineering pipelines and how it differs from basic data quality checks
☁️ How cloud-native architectures, CI/CD pipelines, and real-time data workflows increase integrity risks across ingestion, transformation, and storage
🔍 Where and how data integrity breaks in pipelines, including APIs, Spark transformations, Airflow orchestration, metadata gaps, and data silos
⚙️ Practical approaches to implementing data integrity testing end-to-end, covering batch, streaming, and AI-driven data pipelines
🚀 How to operationalize data integrity using CI/CD, DataOps, and modern tooling to support compliance, scalability, and AI-ready data
Introduction: The Unseen Foundation of Trustworthy Data
The nature of data analytics and automation has caused businesses to make decisions based on this data alone, using only high-level overviews of their quality to assess whether they are ready for a transition to a new model.
However, most businesses do not identify the true depth of the data quality deficiencies that are created when the integrity of the data itself is compromised. Businesses often rely on their ability to move from one platform to another, but if the integrity of the information being migrated is affected, it could lead to incorrect performance and security issues for the company, as well as a risk of violating compliance.
This problem is something Frugal Testing sees frequently when organizations transition to cloud systems, adopt cloud data services, and increase the scale of their data pipelines.
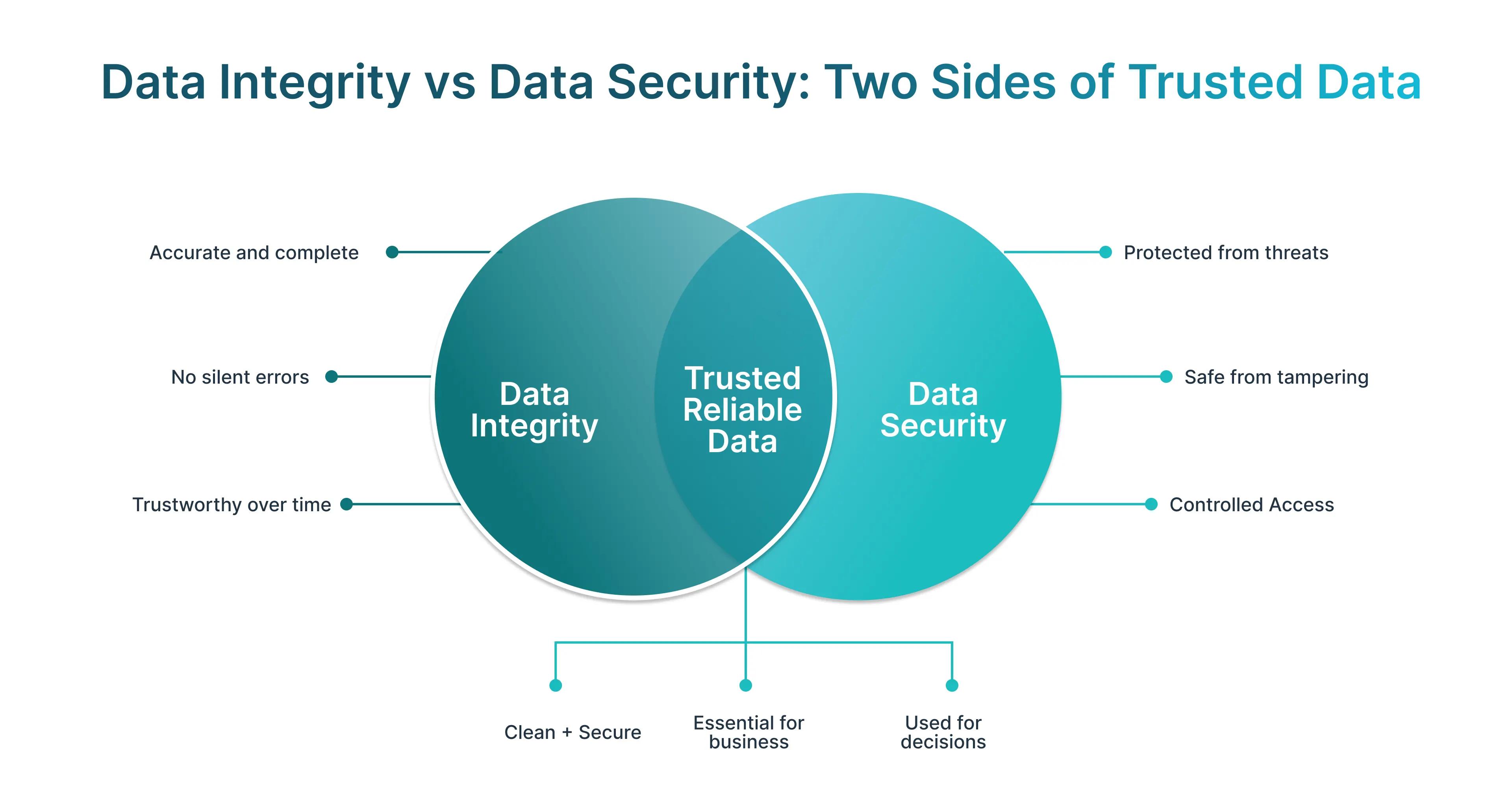
- Data integrity ensures information remains accurate, consistent, and reliable across systems.
- Integrity failures often go undetected in complex data pipelines
- AI models, analytics, and reporting depend on trusted upstream data
- Poor integrity leads to hidden operational and customer-impacting problems
In the end, data integrity testing is more than a technical protection; it is the hidden basis of trust in the data pipeline, the strength of the governance, and confidence in decision-making across the company. Combined, these factors help ensure that business objectives are achieved.
Why Modern Data Pipelines Demand More Than Basic Data Quality
Basic data quality checks like null validation or format rules are no longer enough for today’s distributed data pipelines. With multiple data sources, streaming ingestion, and automated CI/CD pipelines, data can decay, drift, or corrupt without obvious signs. This is especially common in cloud data pipelines supporting real-time analytics and enterprise big data solutions.
- Data moves across ingestion, transformation, and storage layers
- Schema change detection is often missing in fast-moving pipelines
- Automation and orchestration logic increase failure points
- Data overload and velocity amplify integrity risks
To maintain reliable analytics and user experience, organizations must go beyond quality checks and implement data integrity verification throughout the entire pipeline lifecycle.
Understanding Data Integrity in Data Pipelines
Data integrity within your data pipelines means that, throughout the entire process of receiving input into a data pipeline, transforming it, and storing it, the input remains accurate, complete, consistent, and reliable. Because a Data Engineering Pipeline has access to multiple systems and tools across multiple environments, it can be more challenging to ensure that the integrity of your physical, logical, referential, and domain data is maintained as the pipeline grows and scales.
- Entity integrity ensures primary keys are unique and not null
- Referential integrity enforces relationships via foreign keys
- Logical and domain integrity validate business rules
- Physical integrity protects against corruption and storage failures
When integrity principles are embedded into data workflows built on cloud-native solutions. pipelines become resilient, auditable, and scalable across data lakes, data warehouses, and AI-ready environments.
What Data Integrity Means and Why Pipelines Are Uniquely Vulnerable
Data pipelines are uniquely vulnerable because they combine multiple tools, formats, and cloud services. From Change Data Capture to Apache Airflow orchestration and Spark transformations, each step introduces new failure scenarios that traditional testing misses.
- Data ingestion errors from APIs, files, or streaming sources
- Transformation logic silently alters numbers or reference values
- Data silos are forming across data lakes and warehouses
- Broken lineage and missing metadata injection
Without integrity testing, these issues propagate downstream, impacting dashboards, AI models, and compliance reporting. This is why data integrity is foundational to modern data engineering pipelines.
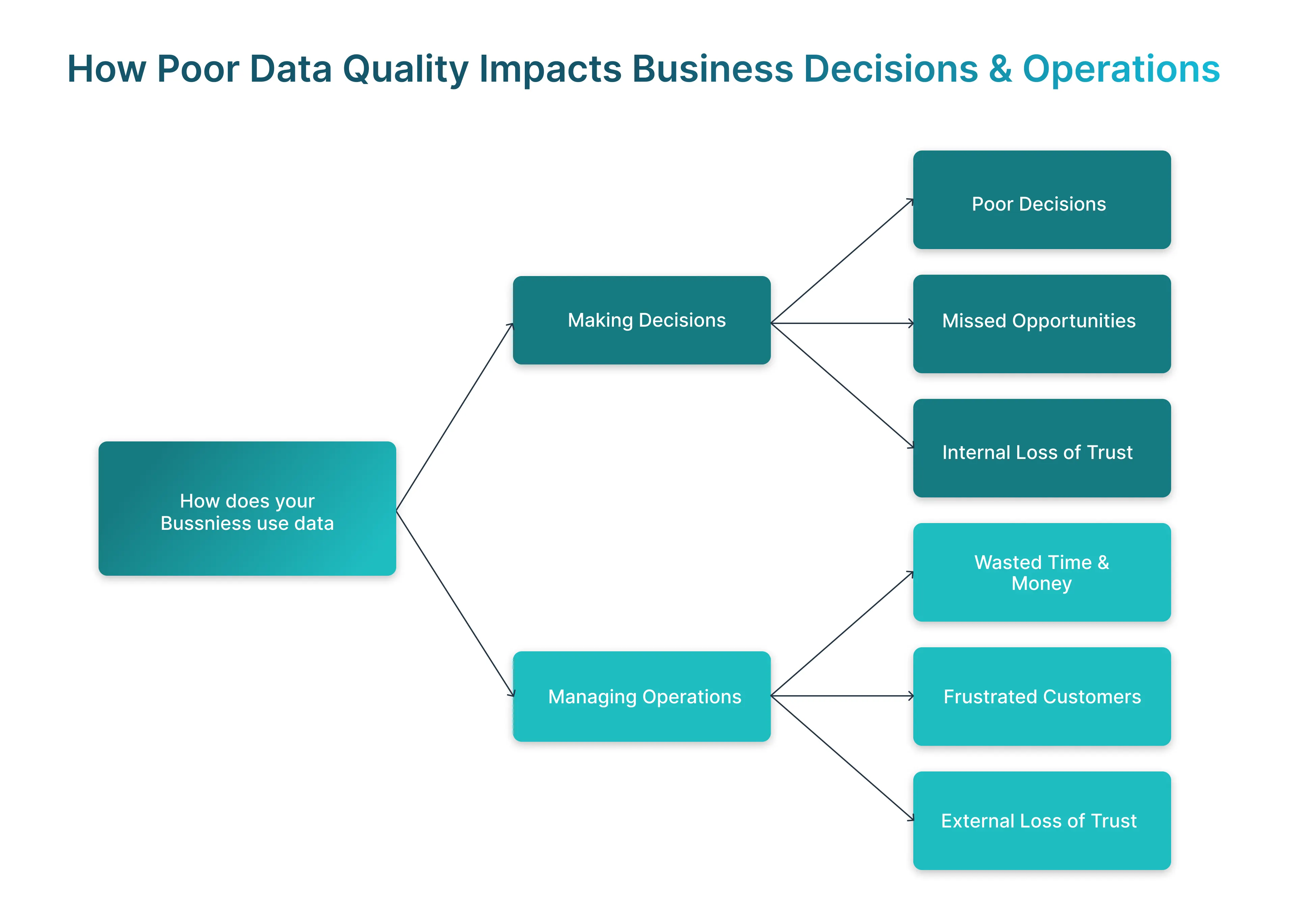
The Hidden Costs of Ignoring Data Integrity Testing
Ignoring data integrity testing creates costs that are often invisible until damage is done. Organizations may meet SLAs on pipeline uptime while still delivering unreliable information. Over time, this erodes trust across analytics teams and business stakeholders.
- Incorrect numbers are driving flawed business decisions
- Reconciliation issues between data sources and reports
- Increased support team workload to investigate discrepancies
- Delayed insights due to repeated manual validation
These problems directly impact performance, customer confidence, and the credibility of the data team, even when surface-level data quality appears acceptable.
Business, Operational, and Compliance Risks of Integrity Failures
Integrity failures also expose companies to regulatory and security risks, particularly in industries subject to regulations such as GDPR, HIPAA, or financial regulations. A single corrupted reference number or IP address can trigger audits and penalties.
- Compliance violations due to inaccurate reporting
- Security issues from tampered or incomplete data
- Failed audits caused by missing data lineage or logs
- Regulatory changes are increasing scrutiny on data governance
Proactive integrity testing helps organizations address these risks early, ensuring data pipelines remain compliant, secure, and audit-ready at scale.
Implementing Data Integrity Testing Across the Pipeline
Effective integrity testing must span the entire data pipeline, not just the final dataset. This includes checks during ingestion, transformation, and storage across cloud infrastructure and on-prem systems.
- Validate data sources during ingestion with checksums and hashing algorithms.
- Enforce data validation rules during transformations
- Use staging tables and temporary tables for controlled verification
- Monitor consistency between data lakes and data warehouses
By embedding integrity checks at every stage, organizations prevent small issues from becoming enterprise-wide problems.
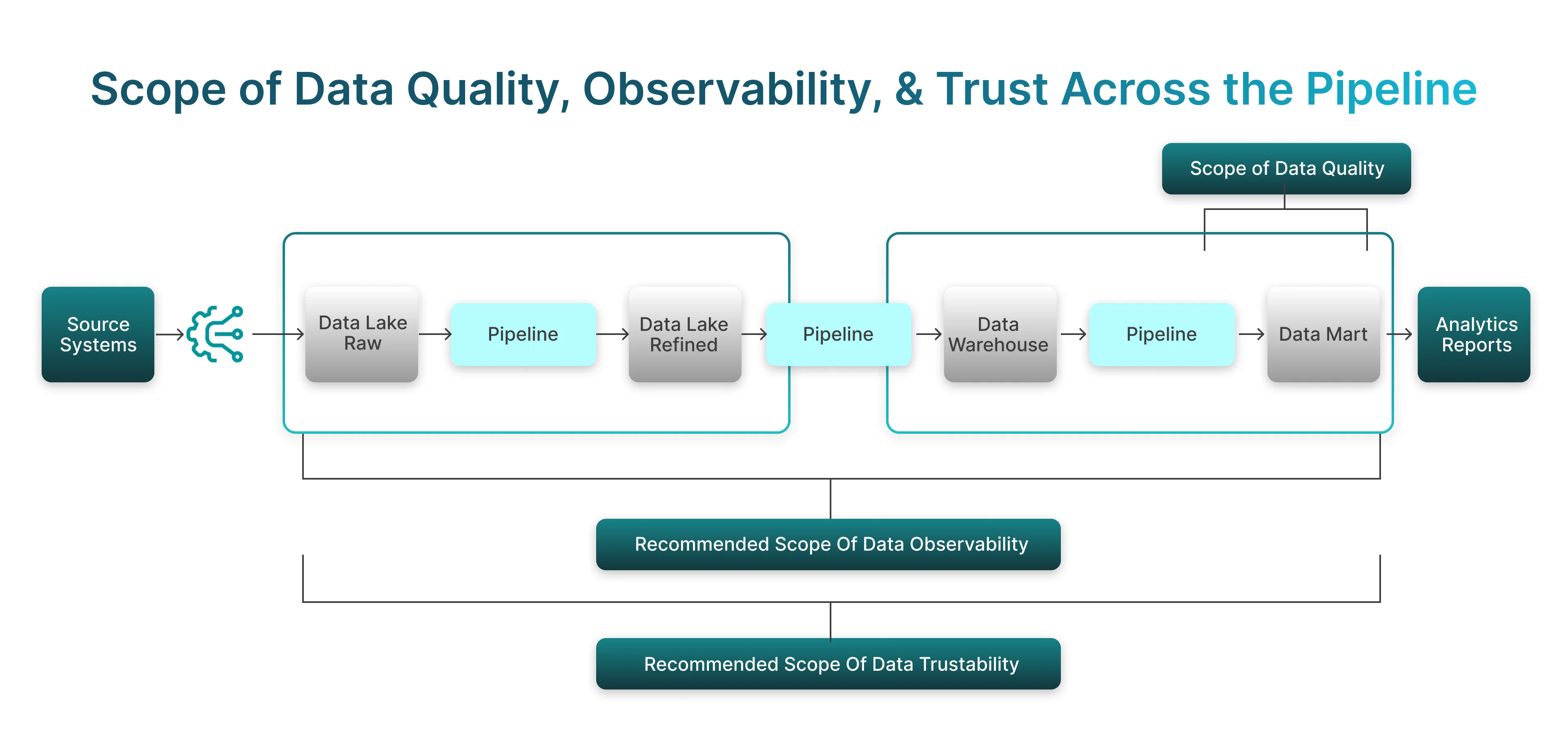
Validating Integrity at Ingestion, Transformation, and Storage
Each pipeline stage requires different integrity strategies. During ingestion, corruption detection and completeness verification are critical. During transformation, consistency validation and business rules matter most. At storage, reconciliation and accuracy checks protect long-term reliability.
- Ingestion: schema validation, completeness checks
- Transformation: unit testing, automated testing, rule validation
- Storage: reconciliation across Snowflake, Redshift, Databricks
This layered approach ensures end-to-end reliability and supports scalable data engineering practices.
Handling Integrity in Real-Time and Streaming Pipelines
Real-time and streaming pipelines add complexity due to velocity and volume. Data drift, late-arriving events, and partial failures are common challenges that require continuous monitoring.
- Stream-level validation using Apache Spark and Cassandra
- Data drift detection for evolving schemas and values
- Near-real-time alerts via Data Observability Platforms
- Performance metrics tied to integrity thresholds
With the right monitoring and automation, even high-speed pipelines can maintain strong data integrity without sacrificing scalability.
Making Data Integrity Testing Operational
To be effective, integrity testing must be operationalized rather than treated as a one-time activity. This means embedding checks into CI/CD practices, DevOps workflows, and DataOps tooling.
- CI/CD pipelines triggering integrity tests on every change
- Version control with lakeFS and Data Version Control
- Automated rollback on integrity failures
- Clear ownership across data teams
Operational integrity testing transforms reliability testing into a continuous discipline rather than a reactive task.
Embedding Integrity Checks into CI/CD, DataOps, and Tooling
Modern tooling makes it easier to integrate integrity checks directly into data workflows. Open-source tools like Great Expectations and Apache Deequ, combined with orchestration platforms, provide strong foundations.
- Airflow-managed integrity tasks
- Docker and Kubernetes for consistent test environments
- Integration with Azure Data Factory and Matillion
- Alignment with broader DataOps strategies
This approach ensures integrity testing scales alongside data pipelines and cloud migration initiatives.
Advanced Integrity Testing for Scalable and AI-Driven Pipelines
As organizations adopt AI models and generative AI tools, integrity testing must evolve further. AI-ready data requires not just correctness, but explainability, lineage, and governance.
- Data profiling to detect anomalies before training
- Golden Record creation via Master Data Management
- Lineage tracking for model transparency
- AI-ready data validation for LLMs and analytics
Advanced integrity testing protects organizations from biased outputs, unreliable predictions, and regulatory exposure in AI-driven systems.
Data Drift, Business Rules, Lineage, and AI-Ready Data
Data drift occurs when data patterns change over time, causing analytics and AI models to behave unpredictably if left unchecked. Detecting these shifts early is critical to maintaining reliable pipeline outputs.
Business rules and data lineage add structure and traceability to evolving pipelines. Together, they ensure AI-ready data remains explainable, auditable, and trustworthy as models and business logic change.
- Drift detection tied to business rules
- Data lineage via catalogs and metadata
- Governance alignment with Gartner-recommended practices
- Continuous integrity checks for AI models
By addressing integrity holistically, organizations ensure AI systems remain trustworthy, compliant, and valuable over time.
Conclusion: Making Data Integrity a Strategic Data Engineering Practice
Data integrity testing is a necessity for businesses today and is considered a strategic decision to ensure the reliability of data pipelines, the scalability of their analysis capabilities, and the ongoing success of AI-enabled innovations. Businesses that consider data integrity central to their data engineering process outperform those that rely on only simple forms of data quality maintenance.
Strong data integrity enables confident business decisions by ensuring analytics and insights are based on reliable information. Proactive testing reduces operational disruptions and compliance risks, while integrated tooling supports scalable automation across data pipelines. Together, trusted data improves customer outcomes, system performance, and long-term business value.
At Frugal Testing, we help organizations embed data integrity testing into their pipelines, CI/CD workflows, and cloud platforms - turning data reliability into a competitive advantage rather than a hidden liability.
People Also Ask (FAQs)
Q1. How is data integrity testing different from traditional data quality checks?
It validates end-to-end data consistency across sources, transformations, and destinations—not just field-level accuracy.
Q2. Can data integrity testing be automated without impacting pipeline performance?
Yes, it can run asynchronously or on sampled data to avoid performance overhead.
Q3. Who is typically responsible for data integrity testing in a data engineering team?
Data engineers usually own it, often in collaboration with QA or analytics teams.
Q4. How often should data integrity tests be reviewed or updated as pipelines evolve?
They should be reviewed whenever pipelines, schemas, or business logic change.
Q5. What early warning signs indicate data integrity issues before failures occur?
Unexpected data volume shifts, schema drift, and metric inconsistencies are common signals.
%201.webp)

