

In recent years, LLM Large Language Models have made a massive leap in how we build intelligent systems—now, they're redefining the world of test automation. These models, trained on massive datasets, can understand and generate human-like text, making them ideal for writing, refining, and maintaining test scripts.
As more QA teams adopt LLM AI technologies like ChatGPT, open source LLM models, and LLM agents, the focus is shifting from traditional scripting to AI-driven automation that’s faster, smarter, and easier to scale.
But what exactly is LLM-Driven Test Automation, and how do tools like LLM RAG, fine tuning LLMs, or integrating with open LLM leaderboard insights help optimize the testing process?
This blog explores how LLM software is used to create maintainable test cases, the impact of LLM fine tuning on accuracy, and how to integrate these AI-generated scripts into real-world QA frameworks. Whether you're experimenting with LLM arena or evaluating the top LLM models, this guide will help you navigate the LLM machine learning landscape in the context of software testing.
What You’ll Learn in This Blog
- How LLMs Generate and Optimize Test Scripts using prompts, datasets, and AI reasoning.
- The Role of ChatGPT and Other Top LLM Models in automating and maintaining test cases.
- How to Validate and Integrate LLM-Generated Scripts into your existing testing frameworks.
- Best Practices for Fine-Tuning LLMs and customizing them for specific QA use cases.
- Future Trends in LLM Software and Open Source LLM Adoption in QA and DevOps
What is LLM-Driven Test Automation?
LLM-driven test automation refers to the use of Large Language Models (LLMs)—a subset of generative artificial intelligence—to automate various testing tasks such as generating test cases, writing scripts, analyzing logs, and even debugging.
Unlike traditional automation tools that rely on rigid scripting, LLMs like ChatGPT understand natural language, allowing testers to describe scenarios in plain English and receive executable test scripts in return.

A key advancement in this space is the integration of Retrieval-Augmented Generation (RAG), an approach where the LLM is paired with an external knowledge base to fetch relevant information before generating output.
Tools like LangChain use retrieval augmented generation architecture to improve the accuracy of AI-generated tests by combining reasoning with real-time retrieval. This blend of artificial intelligence technology and structured data retrieval makes LLM-driven automation smarter, more context-aware, and adaptable to evolving software systems.
By leveraging LLMs and RAG-based workflows, QA teams can streamline testing, reduce manual effort, and achieve faster, AI-assisted quality assurance.
How Large Language Models Are Transforming Test Automation
Large Language Models (LLMs) are revolutionizing how we approach software testing automation by bringing intelligence, adaptability, and speed to the testing process. Traditionally, Selenium automation testing required testers to write detailed scripts and manage every element manually.
Now, LLMs can automatically generate, update, and even explain those scripts by interpreting plain language instructions—reducing complexity and increasing productivity.
These models are enhancing automation testing services by supporting scriptless test creation, smart test maintenance, and adaptive learning from test data.
Whether you're using mobile automation testing tools or performing end-to-end testing automation, LLMs can analyze test cases, identify gaps, and suggest improvements on the fly.
By integrating with automation tools for testing, LLMs are also helping teams accelerate test coverage, reduce manual effort, and minimize errors. As a result, they are becoming key components in modern testing automation tools stacks—making automation software testing more efficient, scalable, and intelligent than ever before.
The Role of ChatGPT in Software Test Automation in 2025
In 2025, ChatGPT is playing a pivotal role in reshaping software test automation by simplifying complex tasks through natural human language inputs. Testers can describe scenarios using plain English, and ChatGPT responds with actionable, executable scripts—turning user queries into intelligent test cases.
This shift toward conversational automation makes the testing process more accessible and enhances the overall user experience.
At the core of ChatGPT’s capability lies the use of pre-trained models, built on vast amounts of data and powered by deep learning models.
These models are then fine-tuned or adapted using domain-specific knowledge to handle a wide array of testing use cases—from unit tests to integration and UI testing. With a focus on optimal performance and output quality, teams are adopting fine-tuned models for more precise, context-aware responses.
The key to unlocking ChatGPT’s full potential lies in Prompt Engineering—crafting effective prompts to guide the model’s behavior. A systematic approach to prompt design can yield valuable insights, while a hybrid approach (combining human review with AI output) ensures the reliability of automated test scripts.
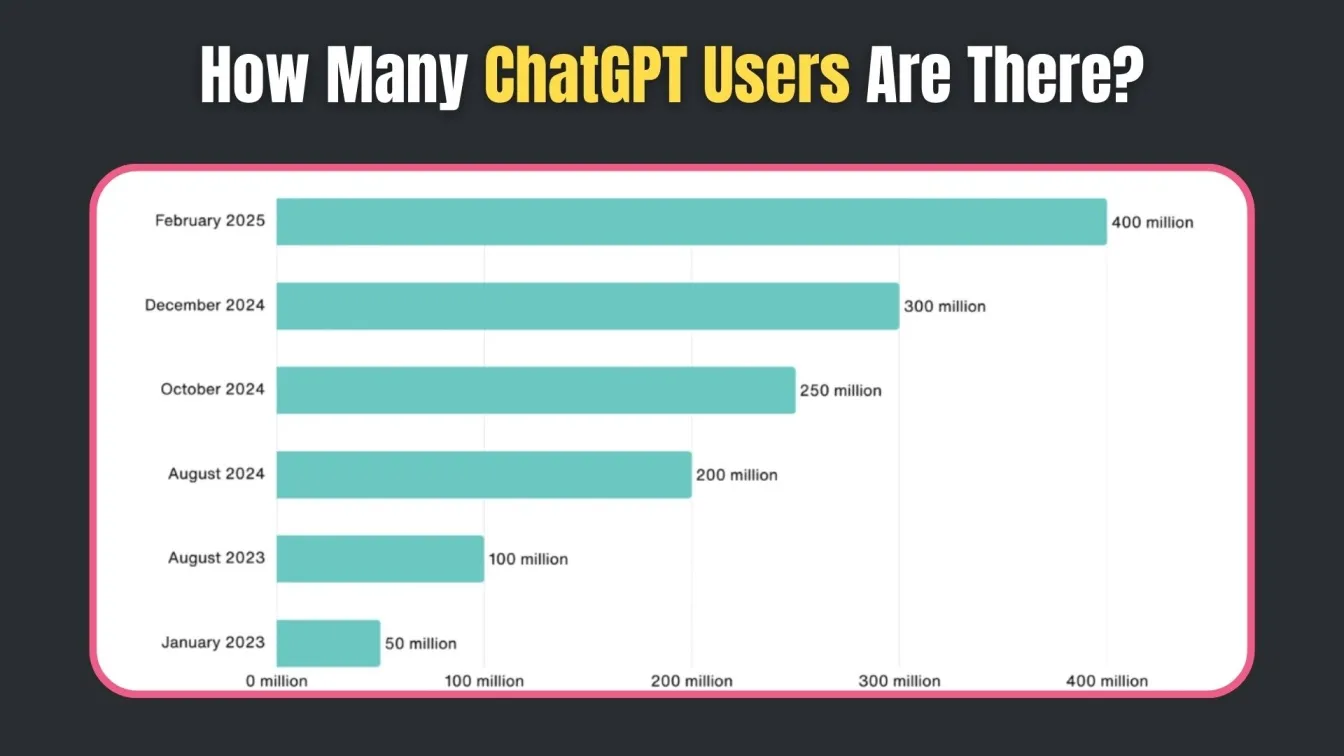
As more QA teams explore practical applications of LLMs, ChatGPT continues to reduce the computational requirements of traditional scripting while delivering a range of applications tailored to modern software testing.
How LLMs Generate Test Scripts from Natural Language Prompts
In traditional software development processes, creating test cases often involved manual testing, extensive manual intervention, and collaboration between the development team and QA. Writing unit tests, crafting integration tests, and building cases for complex test scenarios required significant time and effort—especially when aiming for comprehensive coverage and a robust testing strategy.
Enter Generative AI. These advanced models can transform natural language prompts—like “test login with invalid credentials”—into structured test scripts embedded in a code block. Whether it's unit test generation, functional testing, or end-to-end flows, LLMs can generate context-aware test cases based on user inputs, user interface elements, and even the underlying source code.

By reducing the load of repetitive tasks and speeding up time-consuming tasks, LLMs help teams automate test creation while ensuring better consistency. Unlike traditional methods, which rely on hard-coded rules and human effort, AI-generated scripts adapt dynamically to code updates and evolving requirements.
Moreover, these scripts can be directly integrated into existing testing frameworks and linked with management tools for execution, tracking, and reporting. Teams can measure their pass rate, acceptance rate, and test effectiveness in real-world scenarios, all while reducing reliance on manual scripting and boosting test automation efficiency.
Validating and Refining AI-Generated Test Scripts
Validating and refining test scripts generated by Generative AI involves much more than checking for syntax correctness — it requires an end-to-end process built on neural networks, LLM fine-tuning, and ethical model governance. Today’s general-purpose LLMs, often built as massive models like BERT-style models or generator models, are pre-trained on vast corpora but must be carefully tuned to minimize false positives, harmful responses, and security vulnerabilities.
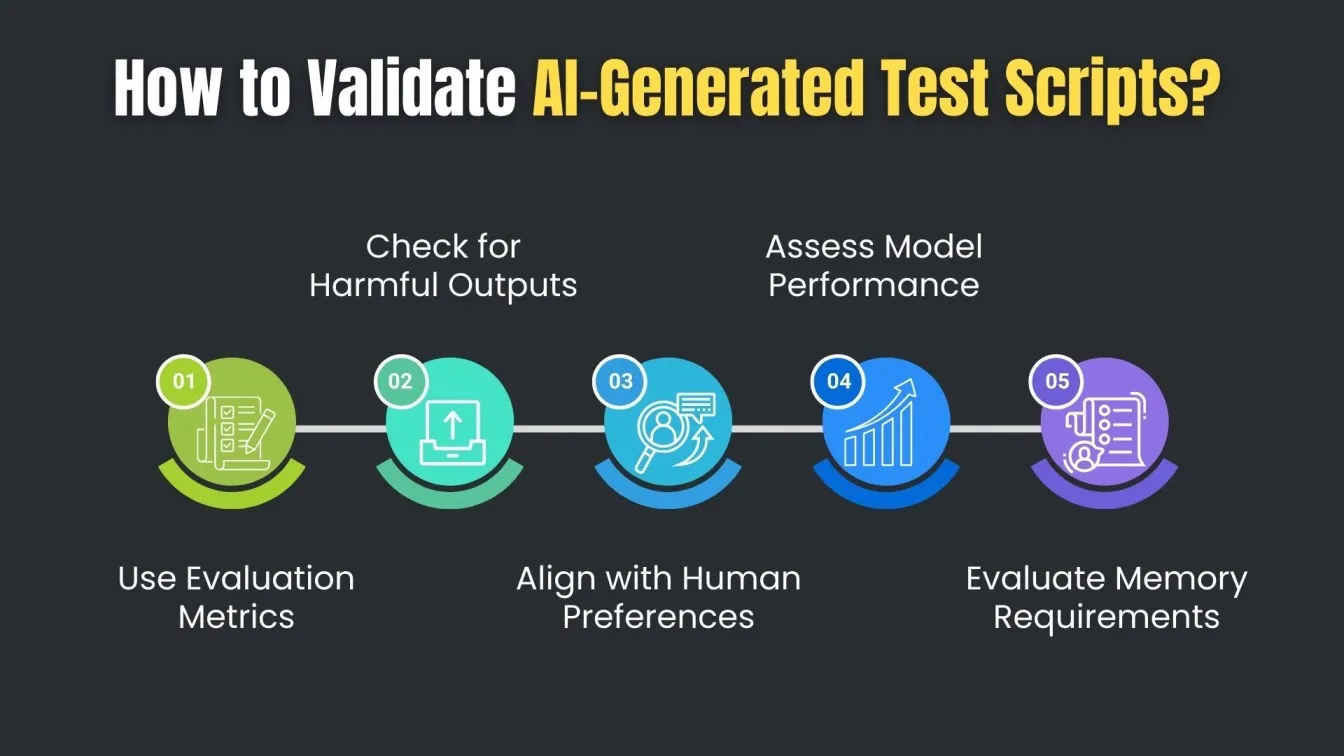
An effective fine-tuning process often includes Federated Fine-Tuning across models across devices and edge devices, enabling updates without compromising local data privacy. Additionally, models must support auditable, transparent fine-tuning practices and rely on real-time feedback loops and human feedback ratings to ensure outputs align with high-impact preferences and human preferences.
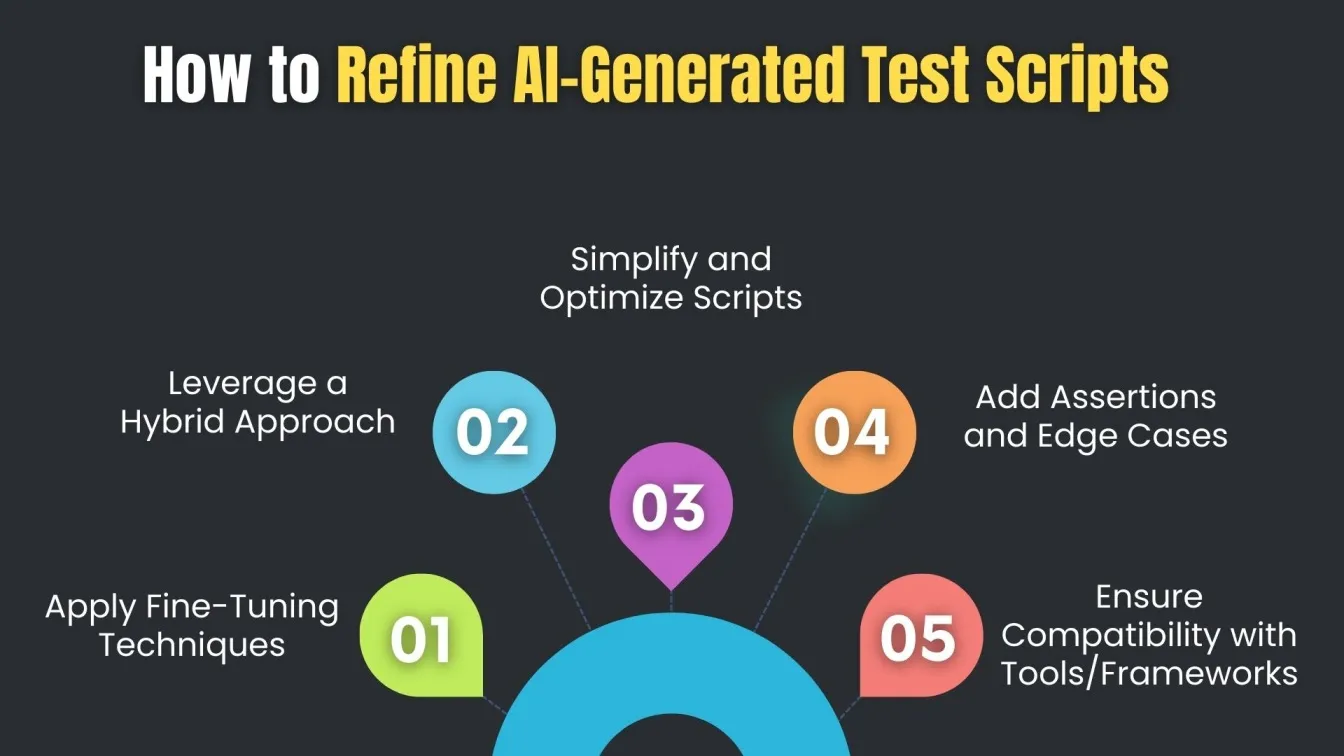
When deploying in low-resource environments, frameworks like TensorFlow Lite for mobile-optimized models are crucial for supporting chatbots for customer support, multilingual customer experiences, and use cases requiring fast inference. LLMs that train models using centralized training or tune on real-world customer data must prioritize coherent sentences, logic coverage, and domain relevance.
Evaluating the Accuracy and Efficiency of LLM-Powered Tests
The use of Generative AI and general-purpose LLMs for automated testing has introduced new possibilities—and new challenges. As teams increasingly rely on generator models and massive models like BERT-style models, evaluating both the accuracy and efficiency of these systems becomes a critical task in ensuring high-quality, reliable test automation.
Accuracy Evaluation: Going Beyond Surface-Level Testing
To evaluate model prediction accuracy, it's essential to verify whether LLM-generated test cases match real-world testing logic and user expectations. However, the biggest challenge arises when LLMs produce false positives, miss edge cases, or generate harmful output due to biases in training. These errors can lead to flawed test coverage and misleading results.
One key risk involves bias from embeddings, especially in tasks like analyzing GPT-4-generated patient notes or testing multilingual applications. Leveraging contrastive learning and incorporating syntactic diversity and demographic diversity in audit datasets helps improve fairness and inclusivity. Human preferences and high-impact preferences must be factored in during evaluation to ensure LLMs generate useful and trustworthy test scripts.
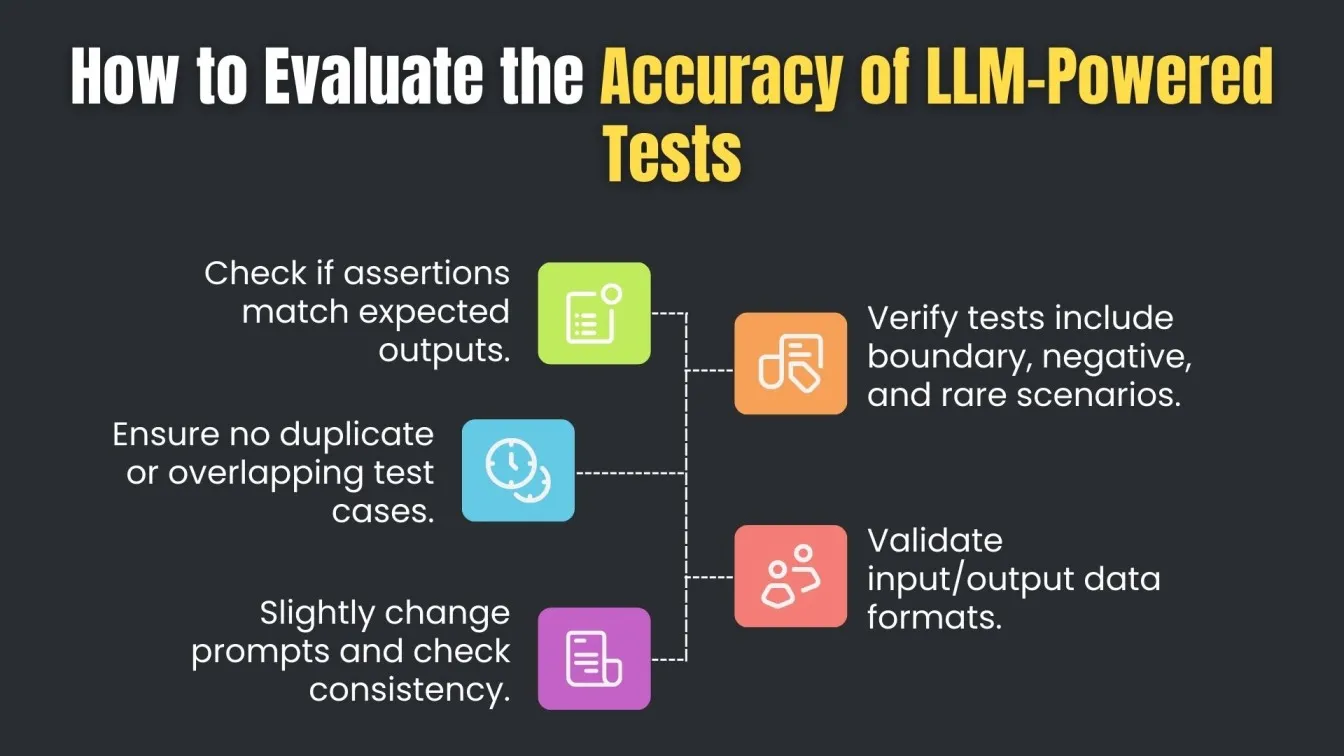
Efficiency Evaluation: Speed, Scalability, and Adaptability
When it comes to efficiency, models across devices, including edge devices, must run lightweight and optimized code. Techniques like TensorFlow Lite, Federated Fine-Tuning, and domain-specific pretraining allow LLMs to operate in distributed environments without compromising performance.
Moreover, minimizing latency and cost through centralized training, Cost-Sensitive Training, and Adversarial training loops ensures that test pipelines stay scalable. Integrating TRL (Transformer Reinforcement Learning) with dynamic reward models further enhances output quality by optimizing for intent accuracy, flow coverage, and test validity.
Integrating LLM-Generated Scripts into Existing Test Frameworks
Integrating scripts generated by Large Language Models (LLMs) into your current testing ecosystem requires careful alignment between automation logic, test structure, and execution flow. With fine-tuned models capable of handling a range of tasks, this integration can significantly accelerate test creation and execution. Here’s how to do it step-by-step:
Analyze LLM Script Output Format
- Understand the structure of the generated script (e.g., test functions, setup/teardown, assertions).
- Identify how well it aligns with your existing test framework conventions.
Choose the Right LLM or Fine-Tuned Model
- Use fine-tuned models trained on your codebase or test scenarios to ensure better compatibility.
- Apply fine-tuning techniques if required to customize output for your framework style (e.g., BDD, TDD, data-driven).
Preprocess and Organize Scripts
- Convert LLM output into modular, reusable functions or test cases.
- Ensure naming conventions, file structure, and annotations match framework standards.

Integrate with Test Runner and Hooks
- Plug LLM-generated tests into your test runner (e.g., pytest, TestNG, Jest, Mocha).
- Add before/after hooks, config files, and environment setups required for smooth execution.
Validate and Debug
- Run the tests and validate logic, assertions, and outputs.
- Check for errors, and false positives/negatives, and fix inconsistencies in the logic.
Optimize for Memory and Performance
- Review memory requirements when running LLM-generated scripts, especially for large or data-intensive tests.
- Optimize loading of fixtures, mock data, or parallel execution where applicable.
Continuous Integration & Version Control
- Add LLM scripts to your CI/CD pipeline.
- Use version control to track changes and improve collaboration across QA teams.
Tools and Platforms That Support LLM-Based Test Automation
Modern tools that support LLM-based test automation are built on a foundation of advanced generator models, including BERT-style models and other massive models capable of handling a wide range of QA tasks. These platforms rely on accurate model prediction and continuous model update processes to generate reliable, real-world test scripts. However, the biggest challenge remains: ensuring consistency, reducing false positives, and mitigating harmful responses, especially in critical domains.
Addressing ethical risks and ethical challenges is also a priority. Tools today adopt contrastive learning, manage bias from embeddings, and account for syntactic diversity and demographic diversity to ensure fairness in test coverage — especially for Multilingual Customer scenarios.
Some platforms also incorporate TRL (Transformer Reinforcement Learning) and dynamic reward models that optimize test generation quality over time. These rely on pairs of inputs and direct text generation to adapt testing logic on the fly. Using mixed embedding strategies further improves model contextual understanding, especially in domains where Leverage datasets include sensitive content, like ratings on chatbot responses or industry-specific QA datasets.
Best Practices for Implementing LLMs in Test Automation
1. Start with Clear Objectives
- Define what you want the LLM to automate — unit tests, API tests, UI tests, or test case generation.
- Clarify success metrics like code coverage, reduction in manual effort, or faster regression cycles.
2. Choose the Right LLM Model
- Use general-purpose models for broad use cases and fine-tuned models for domain-specific testing.
- Evaluate the model’s performance in your programming language and tech stack before adoption.
3. Use Domain-Specific Fine-Tuning
- Fine-tune LLMs using your application’s past test data and codebase for improved accuracy.
- Incorporate edge cases and failed scenarios from previous sprints to make the model smarter.
4. Maintain High-Quality Prompting
- Design well-structured, unambiguous prompts to guide the model toward desired output formats.
- Use examples and context in your prompts to help the model generate consistent and correct test logic.

5. Validate Generated Test Scripts Thoroughly
- Review all outputs manually or with static analysis tools to ensure they align with business logic.
- Run the scripts in a staging environment to detect runtime errors and false assumptions.
6. Integrate with Existing Frameworks
- Make sure LLM-generated scripts are compatible with your current test automation tools and CI/CD pipelines.
- Align generated code with team standards (naming conventions, folder structure, assertions, etc.).
7. Implement Real-Time Feedback Loops
- Collect feedback on test outcomes to retrain or fine-tune the model continuously.
- Use human review signals or test flakiness reports to iteratively improve prompt or model quality.
The Future of LLMs in Test Automation
The future of test automation is being rapidly shaped by the evolution of Large Language Models (LLMs). As these models become more powerful and context-aware, their ability to understand complex software behavior and generate precise, maintainable test cases will only improve. We’re already seeing LLMs go beyond basic test generation to intelligently handle edge cases, generate assertions, and even refactor outdated scripts — tasks that traditionally required skilled testers and developers.
In the near future, we can expect tighter integration of LLMs within the CI/CD pipelines, enabling continuous test generation and validation in real time. With advancements in domain-specific fine-tuning, LLMs will adapt more accurately to business logic, industry standards, and user-specific application behavior. Moreover, they’ll play a central role in shift-left testing, helping developers write test cases at the earliest stages of the SDLC, ultimately speeding up releases and improving software quality.

Another promising direction is the use of LLMs on edge devices and in low-code/no-code testing platforms. This will empower QA professionals and even non-technical users to interact with testing systems using natural language — reducing the skill barrier and improving test coverage across platforms. Combined with advances in reinforcement learning, real-time feedback loops, and ethical safeguards, LLMs are set to become trusted copilots in modern, intelligent QA workflows.
Getting close!!!
This blog provided a comprehensive look into how Large Language Models (LLMs) are revolutionizing the field of software testing by transforming how test scripts are created, managed, and executed. As traditional methods of manual testing become increasingly time-consuming and inefficient, the shift toward AI-driven test automation services is helping QA teams move faster and smarter. Platforms like ChatGPT, open-source LLMs, and RAG-based architectures now allow teams to generate test scripts from natural language, enabling seamless automation of functional, UI, and integration tests.
Companies like Frugal Testing, a leading software testing service provider, are at the forefront of this shift. By offering intelligent, scalable, and highly customizable solutions, Frugal Testing helps clients automate complex testing workflows using the latest advancements in Generative AI. Their expertise in functional testing services ensures that even the most intricate business logic is thoroughly validated using AI-generated test scripts.
The adoption of cloud-based test automation services is also a key enabler in this transformation. With a strong focus on innovation, Frugal Testing continues to deliver forward-thinking AI-driven test automation services that meet the evolving needs of modern software teams, making intelligent testing accessible, efficient, and future-proof.
People Also Ask
What is the process flow of automation tests?
The process flow includes test planning, script design, tool selection, test data setup, execution, and reporting. It ensures repeatable and consistent test validation.
How to validate a large language model?
Validation involves evaluating outputs using benchmark datasets, human feedback, and metrics like accuracy, relevance, and harmful response checks.
What is the implementation strategy of LLM?
Start with a pre-trained model, apply domain-specific fine-tuning, integrate with workflows, and monitor performance through real-time feedback and evals.
What are evals in LLM?
Evals are evaluation frameworks or tools used to systematically measure the performance, safety, and accuracy of LLM outputs across tasks.
How do you implement data-driven instruction?
You collect structured examples, pair inputs with desired outputs, and fine-tune the LLM using supervised learning to align behavior with instructional goals.

%201.webp)

